




数据时代的诗词之问
提起大数据,人们脑海中往往会浮现出自然科学、社会科学、商业经济等领域应用海量数据和复杂算法的场景,而不太会将其与凝聚着文学之美的古典诗词联系起来。仿佛诗词之美可以被感受、允许被讨论,但不能被计算。然而,无论是在学术研究中,还是出于阅读好奇,我们常会碰到这样的问题:
古代各朝有多少诗人?多少女诗人?唐人和宋人哪个更爱写格律诗?宋词有多少词牌?哪个词牌最受词人欢迎?《唐诗三百首》中谁的诗最多?李白与杜甫谁的影响大?唐人七律第一,该颁给崔颢的《黄鹤楼》还是杜甫的《登高》?周邦彦和姜夔谁的音乐水平更高?李白“一生好入名山游”,苏轼“身行万里半天下”,他们到底走了多少地方……
这些问题,有的需要统计数据来作答,有的看似属于艺术判断,实际也需要科学逻辑和数学思维来支撑,有的问题目的不在数量多寡而在具体内容。信息时代的数据思维,给我们认知古典诗词新辟了一扇窗。数据可以是量化的数值,也可以是非量化的信息。无论哪种数据,都有各自的价值和使用场景。
诗词中的量化数据及其作用
传统意义上的数据,指“有根据的数字”,比如靠样本统计获得的量化数据。一个时代或者一个地区的存诗总量、作家人数,或者一位作家的经行地方、创作的某体数量,或者一个选本的选人数量、作品数量,一个词牌的使用次数、使用人数,一首诗词在历代选本中的入选次数、被历代作家唱和的次数等,都属于量化数据。
量化数据可以在样本范围内准确描述研究对象的基本格局。以著名选本《唐诗三百首》为例,蘅塘退士从两千多位唐代诗人的五万多首唐诗中,精选出77家的312首诗分体编成。各体选诗数量为:五古32首、七古28首、五律80首、七律53首、五绝29首、七绝51首、乐府39首。从占比看,古体诗和格律诗的比例近乎一比二。其中五古选诗最多的是中唐诗人韦应物(7首),七古选诗最多的是杜甫和李颀(各5首),五律选诗最多的是杜甫(10首),王维和孟浩然次之(各9首),七律选诗最多的是杜甫(13首),李商隐次之(10首),五绝选诗最多的是王维(5首),七绝选诗最多的是杜牧和李商隐(各7首)。而李白入选的作品大多在乐府(12首)。从选人看,入选率最高的前四位是:杜甫39首、李白29首、王维29首、李商隐24首。可见盛唐诗人最受推崇。杜甫不仅是入选率最高的诗人,也是入选作品覆盖七种诗体的全能型诗人。而在唐代存诗量最多的诗人白居易仅6首作品入选。
这些数据,既能体现作家的创作特点和时代地位,也能反映选家的审美偏好和诗体观念。有的选本流传广远,甚至能够影响一代读者的诗词审美。如果将统计样本横向扩大到其他选本,可考察历代选本的选诗标准和变化特点;如果纵向聚焦某位诗人或相关诗作,还可考察诗人在不同时代的影响力和名篇的稳定性。

▲《唐诗三百首》书影。
量化数据还能为难以公断的某些学术判断提供思路和科学支撑。以文学经典研究为例,“唐人七律第一”是个自古聚讼的话题,“李杜优劣论”也历史悠久。诚然,艺术审美是一种个性化、主观化的体验,很难为审美寻求一份标准,也不必建立这样的标准。但在学术研究中,可以通过“影响力研究”为经典作家和经典作品寻求一种评价方式。衡量一部影视作品的影响力,可以考察其获奖级别、评分情况、重播次数、相关活动等。衡量一首诗词的影响力,也可以通过一系列“指标”来分析,比如选本对于诗词的流传影响深远,评点也能体现诗词在专业领域的关注度,语文教材常常塑造着青少年的诗词印象,文学史则在很大程度上定位了作品的级别。指标有了,再选取一些合适的样本对指标量化,并结合计量科学的特点和文学研究的实际,对数据进行统计计算,就可以在比较客观的前提下得出相对理性的结果。数十年前,王兆鹏教授等专家学者的《寻找经典——唐诗百首名篇的定量分析》《影响的追寻:宋词名篇的定量分析》《唐诗排行榜》《宋词排行榜》等论著,就是基于影响力分析的计量研究成果。
例如在《唐诗排行榜》中,位列榜首的作品是崔颢《黄鹤楼》,这多少有点令人惊讶。再考察其各项指标,会发现这首诗在列入统计样本的33种古代选本中入选率最高,被历代诗论家品评的频次也最高,当代文学史更是无一漏收。可以说,是古今诗选家、诗论家以及文学史的编撰者共同的认可,将这首诗送至榜首。数据背后的信息,还能启发我们考察不同时期诗选家和诗论家对同一首诗歌的关注度,从而用历史性、阶段性的眼光来看待经典的形成过程。这种通过设定指标来量化分析研究对象的思维和做法,比主观好恶的感受更加科学、公允。

▲《唐诗排行榜》书影。
诗词中的属性数据及其价值
进入信息时代,“数据”的内涵也在扩大,而不仅指代“数字”。就诗词而言,还包括反映诗词某类属性的文本或信息,称之为属性数据。一首诗词的作者、标题、诗体、词体、题材、意象、时间、空间,一个作家的姓名、字号、郡望、籍贯、出生地、生卒年、家庭成员、朋友同僚、社会身份,甚至一首格律诗的韵字、对仗,一阕词的词牌、词格,都是诗词的属性数据。
属性数据可为量化数据提供计量基础。前文所述各类统计数值,如某种诗体的数量、某地作家的数量、某个词牌的使用次数等,都基于相关属性的先行标注。属性数据更大的价值在于,可以支撑主题丰富的学习或研究,拓宽诗词认知的边界。
以空间属性为例,诗词中存在各种各样的地名,包括诗词文本中的行政地名、景观地名、意象地名,以及作品的创作地、流传地,还有作家的籍贯地、出生地、任职地、行经地、谪居地、埋葬地等。比如杜甫《闻官军收河南河北》一诗,标题中的“河南”“河北”、诗句中的“剑外”“蓟北”“巴峡”“巫峡”“襄阳”“洛阳”、原诗自注“余家园在东京”中的“东京”等地名,加上这首诗的写作地点“四川省绵阳市三台县”,这些地名指示的地理位置,携带的历史信息,是理解这首作品诗意和作者情感的关键。
诗词中的地名信息,有的比较显而易见,有的需要深度挖掘,有的涉及到悬而未决的学术问题。但长期以来,文学研究中空间观念相对单薄,导致作家年谱的编撰和作品的编年笺注工作,大多重视时序的编排,比较忽略地点的落实。在文学审美中,地名也常被当作专有名词对待,而没有释放出蕴含的能量,发挥应有的作用。这与历史研究中的时空一体观,很不相称。基于这种状况,近年来王兆鹏教授主持的“唐宋文学编年地图”,将空间属性提高到和时间属性同等重要的地位,大量挖掘并标记作家及作品中的各类空间属性数据,并融合历史地理数据,运用GIS技术绘制了唐宋诗人的轨迹地图,实现了年谱的地图化、作品的空间化。
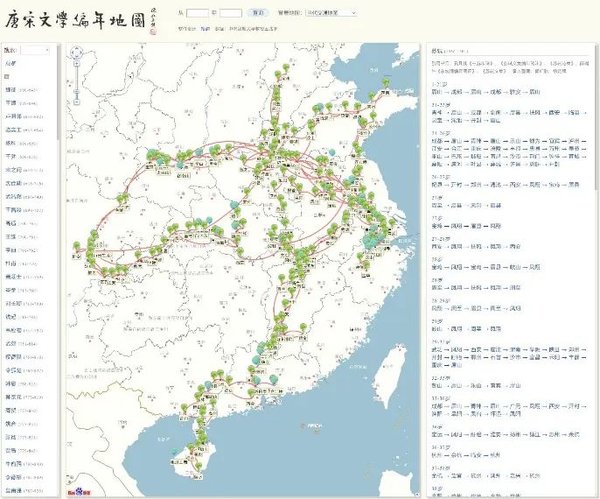
▲“唐宋文学编年地图”之“苏轼行迹图”。
一串串地名,将苏轼从出生、科举、仕宦、贬谪到去世的人生连接成线,将他的诗词文赋、书画创作、平生交游、宦海沉浮,在地图上划出一条独特的东坡印迹。通过这条印迹,读者不仅可以浏览苏轼一生所有编年作品、大事小事,也能清楚指出“黄州惠州儋州”,更会对苏轼“身行万里半天下”、“九死南荒吾不恨”、“一蓑烟雨任平生”的诗句词句,产生别样体会。关注诗词中的空间信息和地名数据,可帮助读者充分了解作家、解读作品,读出背后的信息、情感、美感。
诗词中的地名隐藏着许多历史地理信息,了解这些信息既能辅助诗歌编年系地,还可锻炼读者严谨的科学思维和问题意识。例如,诗词中的古今地名问题。以李白《陪宋中丞武昌夜饮怀古》为例,标题中的“武昌”是个历史地名,想知道其确切所指,要查阅地理文献中“武昌”的地名演变。根据唐代李吉甫《元和郡县图志》和清代顾祖禹《读史方舆纪要》等文献可知,盛唐时期的“武昌”,仍指三国时期孙权改鄂县立武昌郡之“古武昌”,即今天湖北省鄂州市地区。而被今天武汉三镇之“武昌”所用,始于中唐元和年间设立“武昌军”。李白笔下的“武昌”,只能是今天湖北省鄂州市,而不是武汉市。那么盛唐诗人如何指称武汉呢?答案是“江夏”或者“夏口”。李白《江夏送友人》,王维《送康太守》中的“铙吹发夏口”,所指皆武汉。中唐以后,武昌地名两用,如诗人刘长卿的诗句“上下武昌城,长江竟何有”。宋人为作区分,有时仍以“夏口”古地名指称上游的“武昌”,如苏轼《赤壁赋》中“西望夏口,东望武昌”。关注诗词中的古今地名,可以拓展思维。
除了地名数据,诗词中的意象、物象、天象、气象、语典、事典、格律、音韵等数据,每一类都有独特内涵和意蕴,都可衍生出相关话题或研究。数据创新可以激发思维创新,这正是属性数据的巨大魅力。
诗词中的大数据
人们常用大容量、多类型、获取速度快、真实性、非结构化等特点来描述大数据。但这些特点并不适用于所有领域,各个领域对“大”的定义并不相同。
诗词中的大数据,首先反映在数据的体量或容量上。以搜韵网所收古典诗词为例,目前已收录先秦以来古典诗词107万余首,如果完善明清两朝的作品,数量当突破两百万。仅从目前一百多万诗词作品中,就可提取出时间数据58万多条、地名数据近80万条、植物数据近40万条、官职数据约35万条、景观数据54万条、人物数据117万条,合计约四百万,这还不包括句例数据、词汇数据和字数据。尽管这些数据的体量与互联网经济领域动辄以“太字节”(240)计量的数据不可同日而语,但早已超出人的阅读极限和脑力手工的边界。
除了表面的“大容量”,诗词中的大数据,更体现在“大价值”上。诗词中的数据价值,一方面来自数据本身,包括数据精度高、粒度细。从前文所述类型丰富指称具体的地名数据可见一斑。再举对仗数据为例。由于律诗要求中间两联对仗,所以包含大量对仗词汇。计算机从39.3万首律诗和1.5万首排律中,可以获取单字、双字和三字对仗词汇约265万对。从这些数据中筛选出频率高的对仗词汇,并根据对仗的递推特点,可以从任何一个对仗词汇开始,逐级逐词呈现出一张纵横衍伸的对语链。下图是以“清风”为词根的对语链示意。这样的对语链,既能辅助古典诗词创作者参考古人诗句选取对仗词汇,也能辅助语言学者的相关研究。
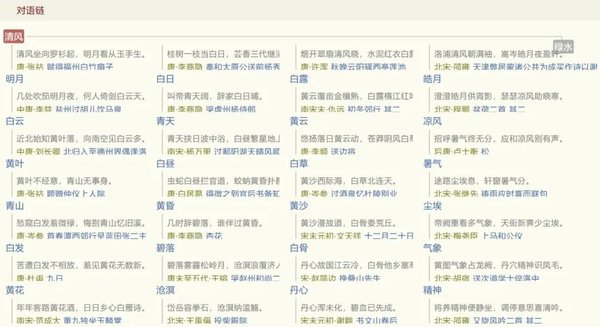
▲搜韵网对语链。
诗词中的数据价值,另一方面来自于数据的交换、整合和分析。以唐宋诗人生平数据为例,其数据精度高、粒度小,但体量不算大,属于小而精的数据。但当这小数据与其他数据整合时却能产生大价值。比如与作品数据整合,能清晰呈现作家人生经历和文学创作的关系;与历史地理数据整合,能将作家的一生行踪在地图上加以呈现;与古代山川驿路等交通数据整合,则有双向的效果,既能为古代交通线路的考察提供重要信息,又能更加细化作家行迹路线;当作家的个人行迹数据在纵向上日益修订而完善,在横向上突破唐宋不断积累形成古今诗人行迹数据,叠加这些行迹还可折射不同时期中心文化城市的变迁现象。
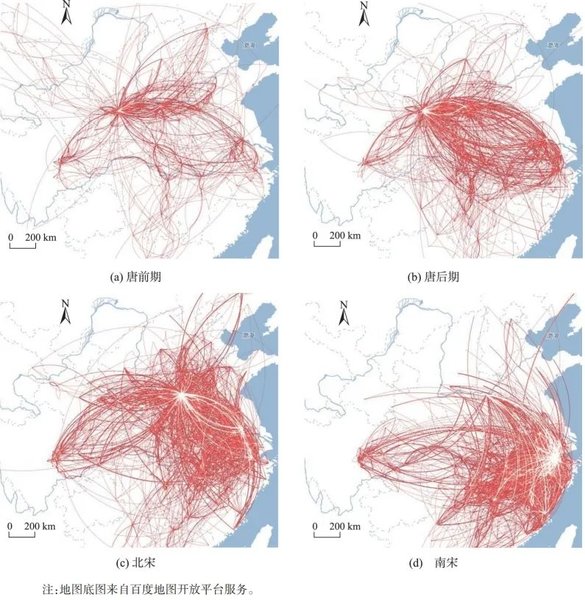
▲唐宋各时期328位文人移动轨迹图。(图片来源:应申等《基于唐宋文人足迹集聚性分析的中心文化城市变迁》,《地球信息科学学报》,2020年第5期)
无论是量化数据,还是属性数据,数据的本质都是信息。当用数据思维认知古典诗词,会发现数据存在之广、传达信息之多,远超想象。培养诗词阅读和诗词研究时的数据思维,锻炼数据敏感度,会读出更多的诗词风景。
作者简介:

邵大为,中南民族大学文学与新闻传播学院青年教师、数字人文资源研究中心主任助理、黄鹤楼文化顾问。主要研究领域为古代文学、文学景观、数字人文。主持教育部人文社科青年项目《宋代方志中的文学景观研究与数据库建设》。在《中国社会科学》《光明日报》《中南民族大学学报》《江汉论坛》等报刊发表论文多篇。
监制 | 杨新华
统筹 | 刘佳 胡俊
编辑 | 郭晖 齐子通
制作 | 胡琪
(编辑:马永)
最新新闻
 zgmzzjw@sina.com
zgmzzjw@sina.com 